在本教程中,我们将详细介绍 SGDR,或在 timm 库中称为 cosine 策略,以及所有支持的超参数。
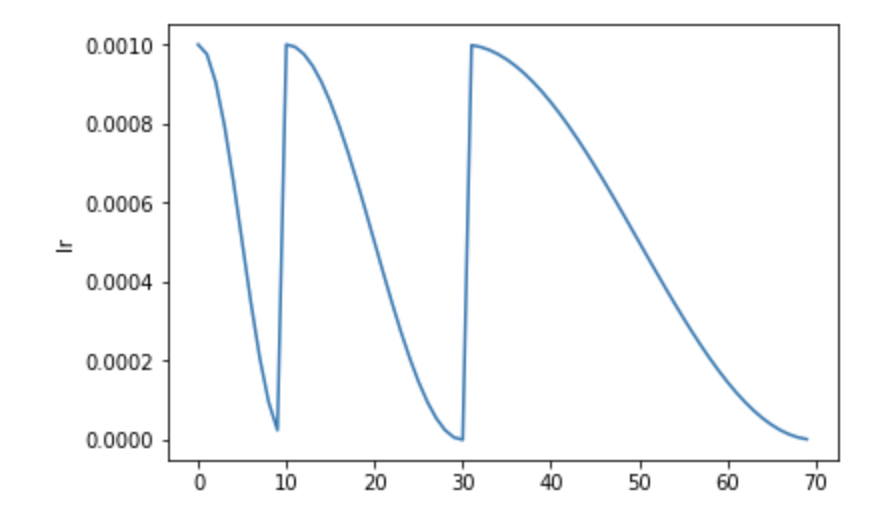
论文 https://arxiv.org/abs/1608.03983 中提到的 SGDR 策略如下所示:
from timm.scheduler.cosine_lr import CosineLRScheduler
from nbdev.showdoc import show_doc
如上所示,CosineLRScheduler 接受一个 optimizer 以及一些超参数,我们将在下面详细介绍这些超参数。我们将首先介绍如何使用 timm 训练文档来训练使用 cosine 学习率策略的模型,然后介绍如何将此策略作为独立策略用于自定义训练脚本。
要训练使用 cosine 策略的模型,我们只需更新传递给训练脚本的参数,通过传入 --sched cosine 参数以及必要的超参数即可。在本节中,我们还将介绍每个超参数如何更新 cosine 策略。
SGDR,但在 timm 中称为 cosine 策略。两者基本相同,仅有细微实现差异。使用 cosine 策略的训练命令如下所示:
python train.py ../imagenette2-320/ --sched cosine
这样我们就开始使用带有所有默认设置的 cosine 策略。现在让我们看看相关的超参数以及它们如何更新退火策略。
这是将用于训练过程的 optimizer。
from timm import create_model
from timm.optim import create_optimizer
from types import SimpleNamespace
model = create_model('resnet34')
args = SimpleNamespace()
args.weight_decay = 0
args.lr = 1e-4
args.opt = 'adam'
args.momentum = 0.9
optimizer = create_optimizer(args, model)
这个使用 create_optimizer 创建的 optimizer 对象会被传递给 optimizer 参数。
初始的 epoch 数。例如,50、100 等。
默认为 1.0。更新 SGDR 策略的退火过程。
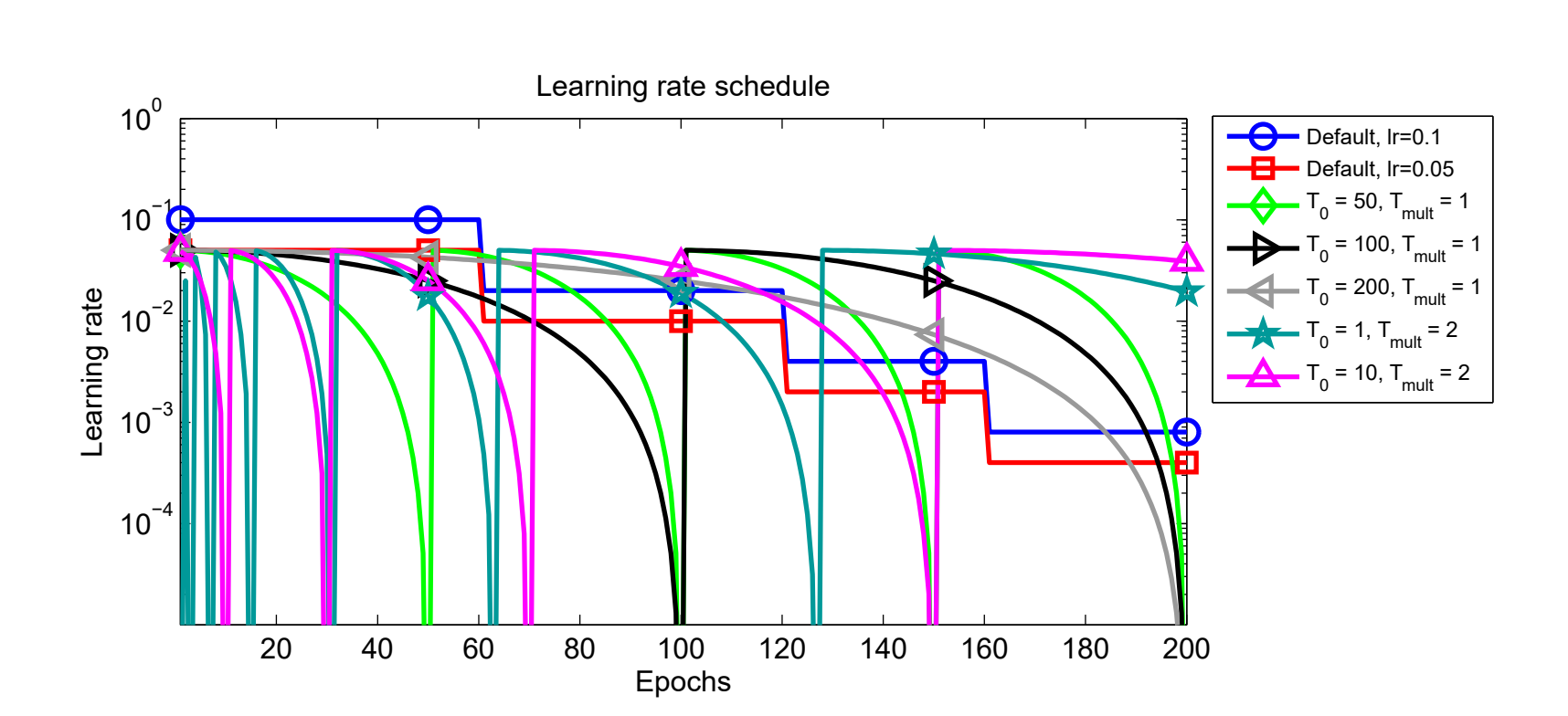
如下图所示,这里的 T0 是 t_initial 超参数,而 Tmult 是 t_mul 超参数。可以看出更新这些参数如何更新策略。
默认为 1e-5。调度期间使用的最小学习率。学习率不会低于这个值。
当 decay_rate > 0 且 <1. 时,每次重启时学习率都会衰减,新的学习率等于 lr * decay_rate。因此,如果 decay_rate=0.5,那么新的学习率将是初始 lr 的一半。
from matplotlib import pyplot as plt
def get_lr_per_epoch(scheduler, num_epoch):
lr_per_epoch = []
for epoch in range(num_epoch):
lr_per_epoch.append(scheduler.get_epoch_values(epoch))
return lr_per_epoch
num_epoch = 50
scheduler = CosineLRScheduler(optimizer, t_initial=num_epoch, decay_rate=1., lr_min=1e-5)
lr_per_epoch = get_lr_per_epoch(scheduler, num_epoch*2)
plt.plot([i for i in range(num_epoch*2)], lr_per_epoch);

num_epoch = 50
scheduler = CosineLRScheduler(optimizer, t_initial=num_epoch, decay_rate=0.5, lr_min=1e-5)
lr_per_epoch = get_lr_per_epoch(scheduler, num_epoch*2)
plt.plot([i for i in range(num_epoch*2)], lr_per_epoch);

定义热身 (warmup) 的 epoch 数。
热身期间的初始学习率。
num_epoch = 50
scheduler = CosineLRScheduler(optimizer, t_initial=num_epoch, warmup_t=5, warmup_lr_init=1e-5)
lr_per_epoch = get_lr_per_epoch(scheduler, num_epoch)
plt.plot([i for i in range(num_epoch)], lr_per_epoch, label="With warmup");
num_epoch = 50
scheduler = CosineLRScheduler(optimizer, t_initial=num_epoch)
lr_per_epoch = get_lr_per_epoch(scheduler, num_epoch)
plt.plot([i for i in range(num_epoch)], lr_per_epoch, label="Without warmup", alpha=0.8);
plt.legend();

正如我们所见,通过设置 warmup_t 和 warmup_lr_init,cosine 策略首先从 warmup_lr_init 的值开始,然后逐渐提升至优化器中设置的 initial_lr(即 1e-4)。从 warmup_lr_init 到 initial_lr 需要 warmup_t 个 epoch。
默认为 False。如果设置为 True,则每个新的 epoch 数等于 epoch = epoch - warmup_t。
num_epoch = 50
scheduler = CosineLRScheduler(optimizer, t_initial=num_epoch, warmup_t=5, warmup_lr_init=1e-5)
lr_per_epoch = get_lr_per_epoch(scheduler, num_epoch)
plt.plot([i for i in range(num_epoch)], lr_per_epoch, label="Without warmup_prefix");
num_epoch = 50
scheduler = CosineLRScheduler(optimizer, t_initial=num_epoch, warmup_t=5, warmup_lr_init=1e-5, warmup_prefix=True)
lr_per_epoch = get_lr_per_epoch(scheduler, num_epoch)
plt.plot([i for i in range(num_epoch)], lr_per_epoch, label="With warmup_prefix");
plt.legend();

在上面的示例中,我们可以看到 warmup_prefix 如何更新学习率退火策略。
SGDR 中最大重启次数。
num_epoch = 50
scheduler = CosineLRScheduler(optimizer, t_initial=num_epoch, cycle_limit=1)
lr_per_epoch = get_lr_per_epoch(scheduler, num_epoch*2)
plt.plot([i for i in range(num_epoch*2)], lr_per_epoch);

num_epoch = 50
scheduler = CosineLRScheduler(optimizer, t_initial=num_epoch, cycle_limit=2)
lr_per_epoch = get_lr_per_epoch(scheduler, num_epoch*2)
plt.plot([i for i in range(num_epoch*2)], lr_per_epoch);

如果设置为 False,则 epoch t 返回的学习率为 None。
num_epoch = 50
scheduler = CosineLRScheduler(optimizer, t_initial=num_epoch, t_in_epochs=False)
lr_per_epoch = get_lr_per_epoch(scheduler, num_epoch)
lr_per_epoch[:5]
向学习率策略添加噪声。
要添加的噪声量。默认为 0.67。
噪声标准差。默认为 1.0。
要使用的噪声种子。默认为 42。
如果设置为 True,则将属性 initial_lr 设置到每个参数组。默认为 True。