timm 支持多种基于图像任务的预训练和非预训练模型。
要获取完整的模型列表,请使用 timm 中的 list_models 函数,如下所示。list_models 函数返回按字母顺序排列的 timm 支持的模型列表。我们只看下面的前 5 个模型。
import timm
timm.list_models()[:5]
通常,您总是希望使用 timm 中的工厂函数。特别是,您希望使用 timm 中的 create_model 函数来创建任何模型。可以使用 create_model 函数创建 timm.list_models() 中列出的任何模型。还有一些很棒的额外功能我们稍后会介绍。但是,让我们看一个快速示例。
import random
import torch
random_model_to_create = random.choice(timm.list_models())
random_model_to_create
model = timm.create_model(random_model_to_create)
x = torch.randn(1, 3, 224, 224)
model(x).shape
在上面的示例中,我们随机选择 timm.list_models() 中的一个模型名称,创建它并向模型传递一些虚拟输入数据以获得输出。通常,您绝不应该像这样创建随机模型,这只是一个示例,用于展示 timm.list_models() 中的所有模型都受 timm.create_model() 函数支持。使用 timm 创建模型就是这么简单。
当然!timm 旨在让研究人员和实践者能够轻松实验,并支持大量带有预训练权重的模型。这些预训练权重要么是
- 直接使用自其原始来源
- 由 Ross 从其在不同框架(例如 Tensorflow 模型)中的原始实现移植而来
- 使用包含的训练脚本 (
train.py) 从头开始训练。训练这些单独模型的具体命令和超参数在Training Scripts下提及。
要列出所有具有预训练权重的模型,timm 提供了一个方便的参数 pretrained,可以在 list_models 函数中传递,如下所示。我们只列出返回的前 5 个模型。
timm.list_models(pretrained=True)[:5]
timm 目前还没有像 cspdarknet53_iabn 或 cspresnet50d 这样的模型的预训练权重。对于具有硬件可用性的新贡献者来说,这是一个很好的机会,他们可以使用训练脚本在 Imagenet 数据集上预训练模型并分享这些权重。您可能已经知道,ImageNet 数据包含 3 通道 RGB 图像。因此,为了能够在大多数库中使用预训练权重,模型期望输入是 3 通道图像。
import torchvision
m = torchvision.models.resnet34(pretrained=True)
# single-channel image (maybe x-ray)
x = torch.randn(1, 1, 224, 224)
# `torchvision` raises error
try: m(x).shape
except Exception as e: print(e)
从上面可以看出,这些来自 torchvision 的预训练权重无法与单通道输入图像一起使用。作为一种变通方法,大多数实践者通过复制单通道像素来创建 3 通道图像,从而将单通道输入图像转换为 3 通道图像。
基本上,上面的 torchvision 在抱怨它期望输入有 3 个通道,但却得到了 1 个通道。
# 25-channel image (maybe satellite image)
x = torch.randn(1, 25, 224, 224)
# `torchvision` raises error
try: m(x).shape
except Exception as e: print(e)
同样,torchvision 会抛出错误,这一次除了不使用预训练权重并从随机初始化的权重开始外,没有其他方法可以绕过此错误。
m = timm.create_model('resnet34', pretrained=True, in_chans=1)
# single channel image
x = torch.randn(1, 1, 224, 224)
m(x).shape
我们向 timm.create_model 函数传入参数 in_chans,然后这一切就像魔法一样奏效了!让我们看看 25 通道图像会发生什么?
m = timm.create_model('resnet34', pretrained=True, in_chans=25)
# 25-channel image
x = torch.randn(1, 25, 224, 224)
m(x).shape
这又奏效了!:)
timm 在用于加载模型预训练权重的 load_pretrained 函数内部完成了所有这些神奇的操作。让我们看看 timm 如何实现预训练权重的加载。
from timm.models.resnet import ResNet, BasicBlock, default_cfgs
from timm.models.helpers import load_pretrained
from copy import deepcopy
下面,我们创建一个简单的 resnet34 模型,它可以接受单通道图像作为输入。通过在创建模型时向 ResNet 构造类传入 in_chans=1 来实现这一点。
resnet34_default_cfg = default_cfgs['resnet34']
resnet34 = ResNet(BasicBlock, layers=[3, 4, 6, 3], in_chans=1)
resnet34.default_cfg = deepcopy(resnet34_default_cfg)
resnet34.conv1
resnet34.conv1.weight.shape
从上面的 resnet34 的第一个卷积层可以看出,输入通道数设置为 1。并且 conv1 权重的形状是 [64, 1, 7, 7]。这意味着输入通道数为 1,输出通道数为 64,卷积核大小为 7x7。
但是预训练权重呢?由于 ImageNet 包含 3 通道输入图像,所以这个 conv1 层的预训练权重应该是 [64, 3, 7, 7]。下面来确认一下
resnet34_default_cfg
让我们加载模型的预训练权重,并检查 conv1 期望的输入通道数。
import torch
state_dict = torch.hub.load_state_dict_from_url(resnet34_default_cfg['url'])
太好了,我们已经从 URL 'https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet34-43635321.pth' 加载了 resnet-34 的预训练权重,现在让我们检查一下下面 conv1 权重的形状
state_dict['conv1.weight'].shape
所以这一层期望的输入通道数为 3!
conv1.weight 的形状是 [64, 3, 7, 7],这意味着输入通道数是 3,输出通道数是 64,卷积核大小是 7x7。conv1 层权重的形状会是 [64, 1, 7, 7],因为我们将输入通道数设置为 1。希望上面我们看到的这个异常现在更有意义了:给定 groups=1,权重大小为 [64, 3, 7, 7],期望输入 [1, 1, 224, 224] 有 3 个通道,但实际得到了 1 个通道。timm 内部的 load_pretrained 函数中发生了一些非常巧妙的事情。基本上,当期望的输入通道数不等于 3 时,有两种主要情况需要考虑。输入通道数是 1 或者不是 1。让我们看看这两种情况会发生什么。
当输入通道数不等于 3 时,timm 会相应地更新预训练权重的 conv1.weight,以便能够加载预训练权重。
如果输入通道数为 1,timm 只需将 3 个通道的权重求和到一个单通道中,以将 conv1.weight 的形状更新为 [64, 1, 7, 7]。这可以通过以下方式实现
conv1_weight = state_dict['conv1.weight']
conv1_weight.sum(dim=1, keepdim=True).shape
>> torch.Size([64, 1, 7, 7])
因此,通过更新第一个 conv1 层的形状,我们现在可以安全地加载这些预训练权重。
在这种情况下,我们只需根据需要重复 conv1_weight 多次,然后选择所需数量的输入通道权重。
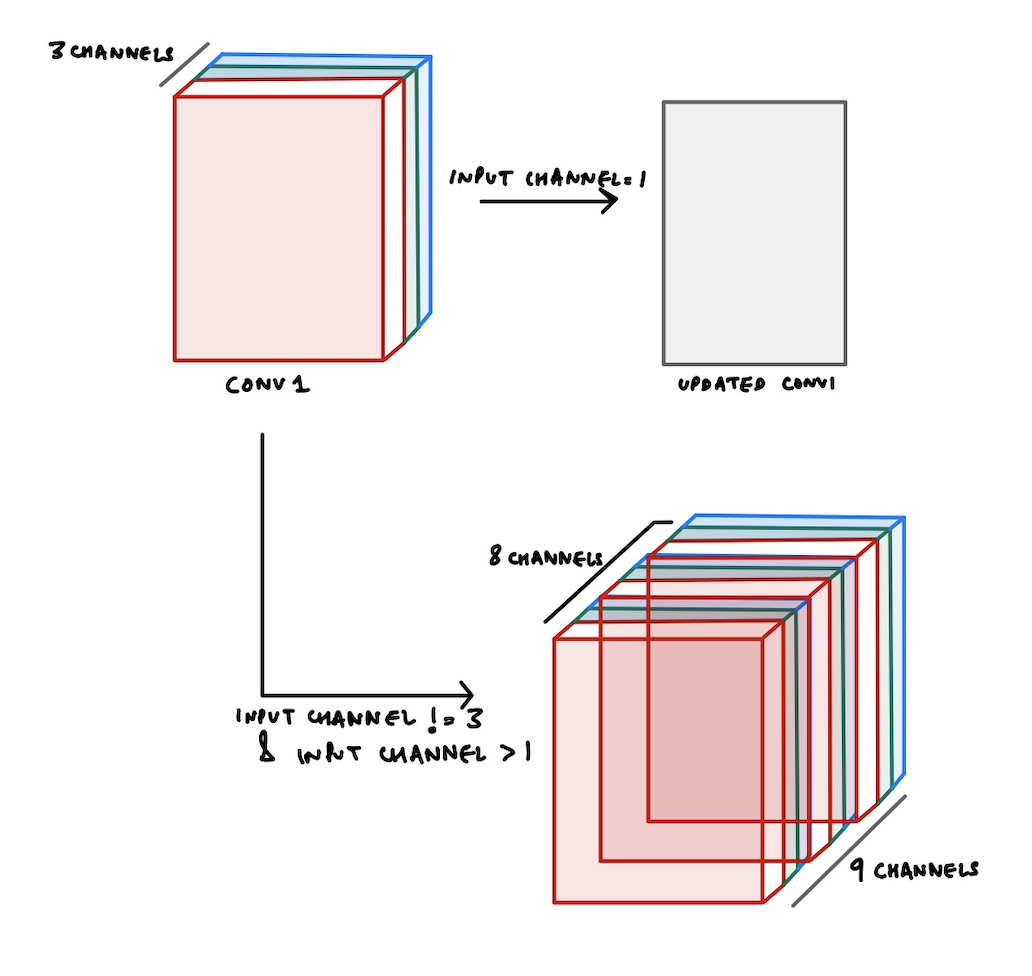
如上图所示,假设我们的输入图像有 8 个通道。因此,输入通道数等于 8。
但是,正如我们所知,我们的预训练权重只有 3 个通道。那么我们如何仍然能够利用预训练权重呢?
好吧,timm 中发生的事情已在上图中显示。我们将权重复制 3 次,这样总通道数就变成了 9,然后我们选择前 8 个通道作为 conv1 层的权重。
所有这些都在 load_pretrained 函数内部完成,如下所示
conv1_name = cfg['first_conv']
conv1_weight = state_dict[conv1_name + '.weight']
conv1_type = conv1_weight.dtype
conv1_weight = conv1_weight.float()
repeat = int(math.ceil(in_chans / 3))
conv1_weight = conv1_weight.repeat(1, repeat, 1, 1)[:, :in_chans, :, :]
conv1_weight *= (3 / float(in_chans))
conv1_weight = conv1_weight.to(conv1_type)
state_dict[conv1_name + '.weight'] = conv1_weight
因此,如上所示,我们首先重复 conv1_weight,然后从这些复制的权重中选择所需数量的 in_chans。